AMD's GAIA Defaults To Better Model, Continued Improvements For Local AI
…get local AI agents running on your AMD hardware whether it's on Windows or Linux. With GAIA 0.17.5, they have replaced Qwen 3.5 35B with Gemma 4 E4B…
Tracked topic
Gemma is a family of open-weight language models released by Google for text generation and related NLP tasks.
…get local AI agents running on your AMD hardware whether it's on Windows or Linux. With GAIA 0.17.5, they have replaced Qwen 3.5 35B with Gemma 4 E4B…
…Google says this makes it faster and more efficient when running on local hardware like an Nvidia DGX or a humble gaming GPU. Most AI models are designed to be autoregressive—they…
…Lemonade 10.1 is now available for Windows and Linux users to assist in running local AI apps primarily with AMD Ryzen and AMD Ryzen AI hardware while also being able to…
…with Google’s Gemma 4 architecture. Up to 4x faster performance: The boost means fast text generation, where single-user generation usually stalls — on local hardware. Open and local: DiffusionGemma is open…
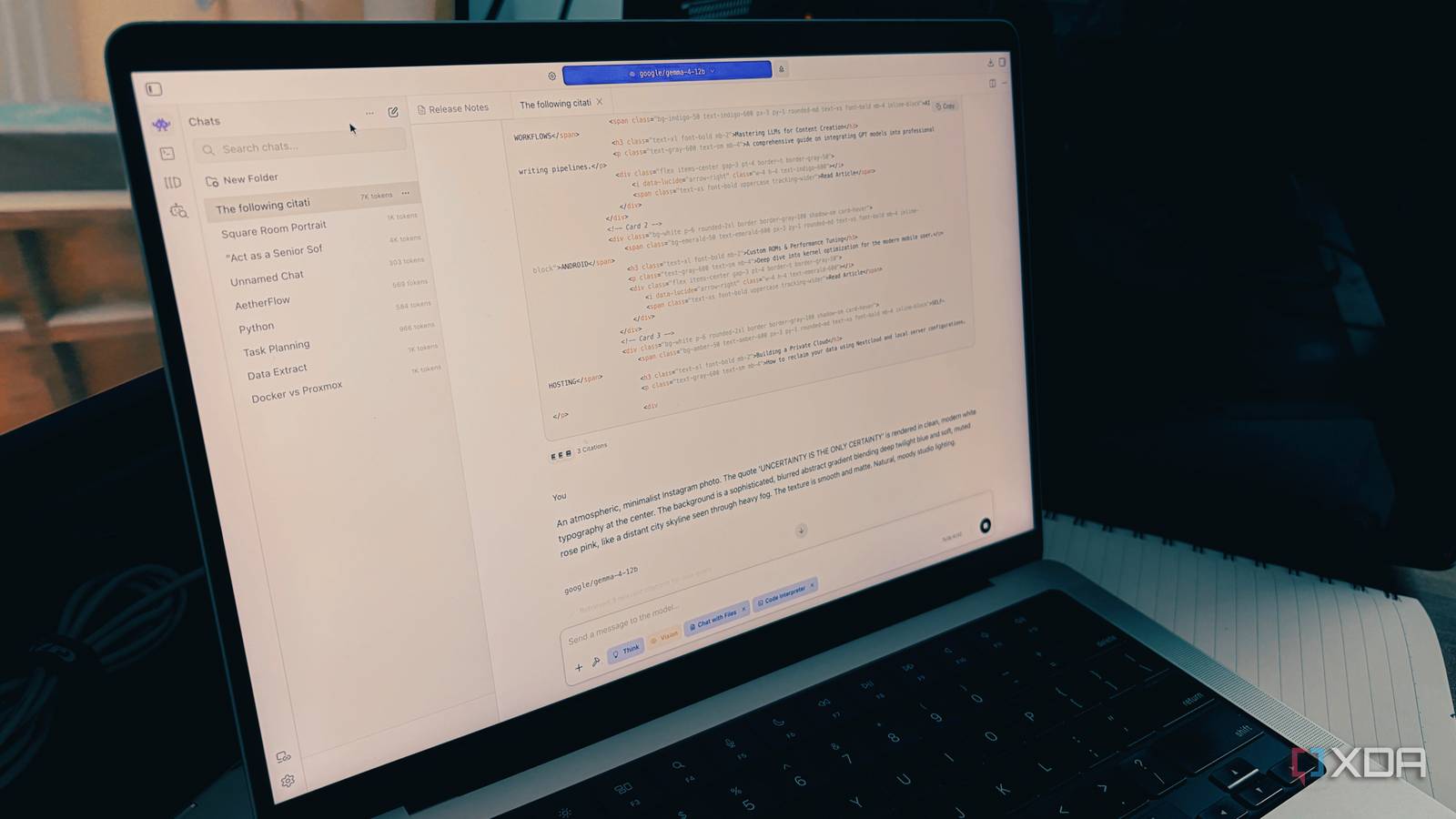
…Sign in to your XDA account Summary Local AI runs on modest PCs - no RTX needed; efficient small models work on CPU and iGPU. Sub-1B models feel instant for simple tasks…
…But apparently someone has made an SXM2-to-PCIe adapter, and with that and a cooling mod, the V100 was more than capable of running LLMs locally. The adapter cost another $100…
…I wrote a Python script that uses Gemma 4 31b, running locally on my PC, to identify the game in each clip and sort the files automatically. It actually works, and it…
I made my first macOS utility app that ships with a bundled Gemma 4 model, specifically the Gemma E4B one. It made my app DMG have 5.3 GB in size, but I think it is a small size for the power that this free local model c…
Gemma just crushed Qwen in a local LLM gamedev contest! Device: MacBook Pro M5 Max, 64GB RAM Qwen 3.6 27B: 32 tokens/sec · 18m 04s · 33,946 tokens. Gemma 4 31B: 27 tokens/sec · 3m 51s · 6,209 tokens. So what is more impo…
Hi guys.I have been working on Hitoku Draft, an open-source, voice-first AI assistant that runs entirely locally. I posted about it already, and now it has also transcription with voice editing. Looking for feedback, as …
Update from the lawyer with the V100 server. A few of you asked what I actually ended up running once the dust settled, so here it is. Still just a lawyer, still driving the whole thing through Claude Code, still not ful…
Claude Code like agentic workflow ai too costly for me.Any LLM can I run with VSCode at the below setup? 16ram Intel core i7 h processor 13gen 512gb NVMe SSD I want to run the ai as local agentic workflow with Vscode.I w…
…Sign in to your XDA account Running a single local LLM on your own hardware is one thing. Running two of them at the same time, on the same machine, with shared…
…The two models I keep coming back to are Qwen 3.5 9B and Gemma 4 E4B, both running fine on my 8GB VRAM, so hardware isn't really the bottleneck for…
…if running on devices with slower memory, like a notebook or consumer graphics card. Both of these models feature a 256,000-token context window, making them appropriate for local code assistants…