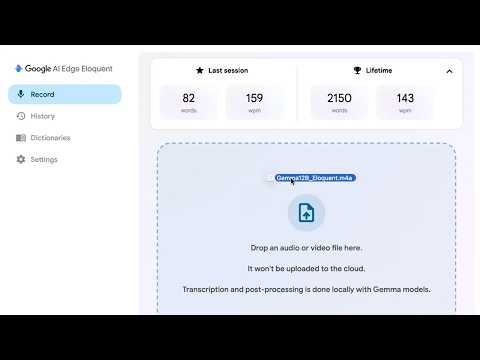
Recent signals
-
Gemma 4's smallest model runs on 3GB of VRAM, and it's the one I actually reach for
XDA-Developers
-
Gemma 12b less than 10 watts 6.5pp 1.3tg
-
Qwen 3.6 35B-A3B @ Q4 or Gemma 4 12B @ Q8?
r/LocalLLaMA