I ditched Claude, ChatGPT, NotebookLM, and Perplexity for these free open-source tools
…With local LLMs , you get to escape all of that. Local LLMs are AI models that run directly on your computer's hardware, and you can use them at any time (even…
Tracked topic
Gemma is a family of open-weight language models released by Google for text generation and related NLP tasks.
…With local LLMs , you get to escape all of that. Local LLMs are AI models that run directly on your computer's hardware, and you can use them at any time (even…
…Say you're setting up a local LLM for coding, and you settle on three options: Devstral 2 123B, Qwen3 Coder Next 80B, and Gemma 4 31B. Devstral 2 is the most…
…So you're not waiting on your runner to catch up to use the newest open weights. Related Ollama is still the easiest way to start local LLMs, but it's the…
…Local LLMs aren't really necessary, but they were in this case Most of us can skip local LLMs and be completely fine without them. They're not actually necessary, but we…
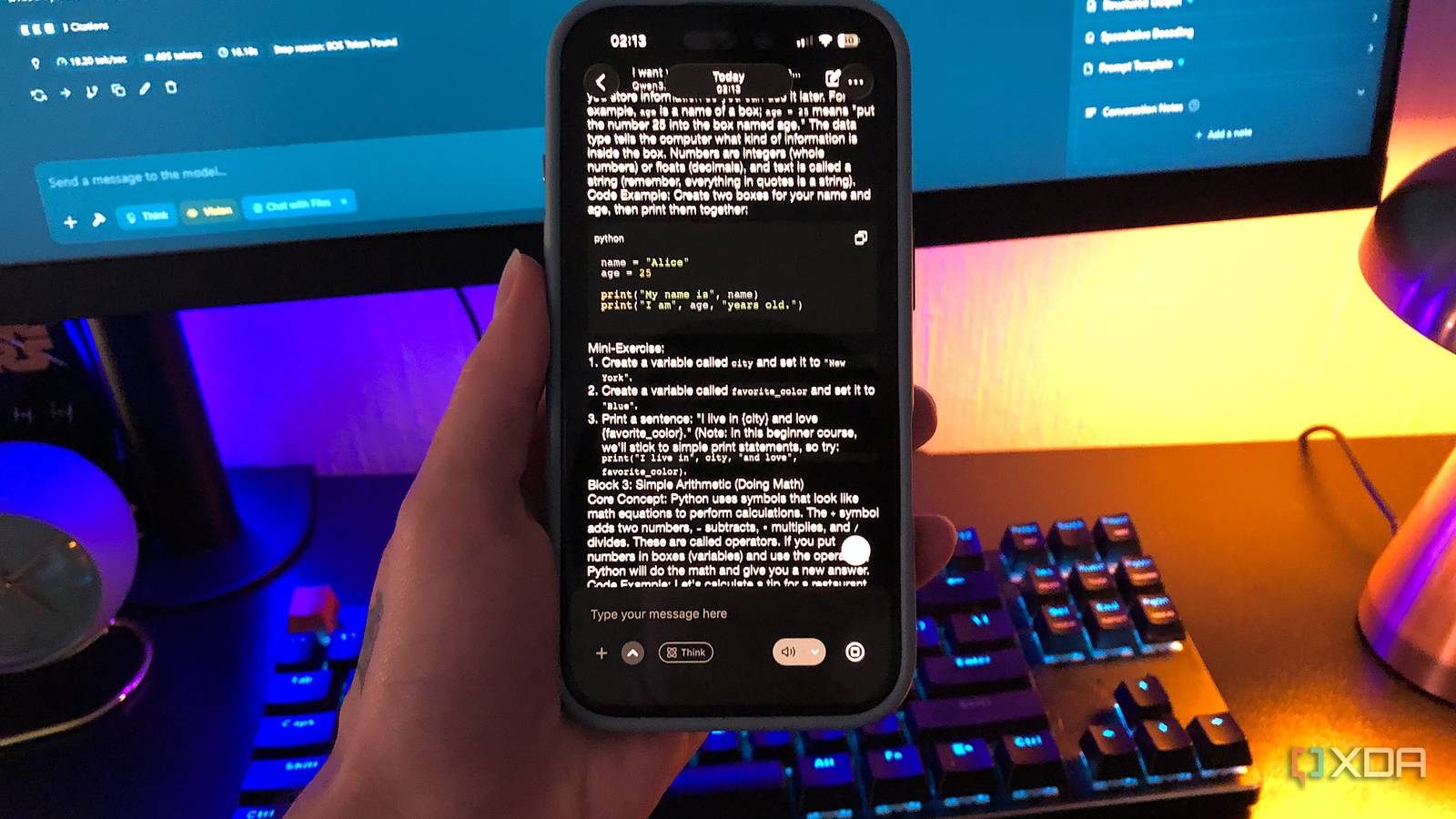
…Local LLMs aren’t just chatbot replacements Having spent hours configuring the right LLM pipelines for my FOSS models, I have to admit that local AI tools are far more useful than…
…So what does this tell us? Well, your local AI agent doesn't need to be big. It just needs to be good at calling tools. Model size doesn't predict tool…
…I can put my old graphics cards to good use Like most LLM-hosting enthusiasts, I started my journey by hosting local models on Ollama , and it served me well for the…
…Turns out, the cluster’s performance was worse than a standalone SBC I blame slow network provisions for this bottleneck Since I was using the fairly lightweight Gemma 3 4B, I expected…
…Llama, Gemma, and Deepseek. I opted to install the smallest version of each model, as I only had 32GB of space on the SD Card. Using LLMs on the SBC was responsive…
…It ain’t perfect, but it’s a decent secondary LLM server I’ve got a Gemma4-26B-A4B instance that runs on my GTX 1080 24/7, and I use it…